
Gopal Goel

Santhosh Kumar Manavasi Lakshminarayanan

Brian Xu

Shriram Sridharan

GLM-5.2 vs Frontier Models on Real Customer Slide Decks in Revenue Agents
70% of the time we asked GLM-5.2 to generate a slide deck, it didn’t.
We ran a head-to-head eval on production slide deck tasks across Opus 4.8, Opus 4.7, GPT-5.5 (high), and GLM-5.2.
Opus wins on deck quality & GLM wins on cost per usable deck.
Quick highlights:
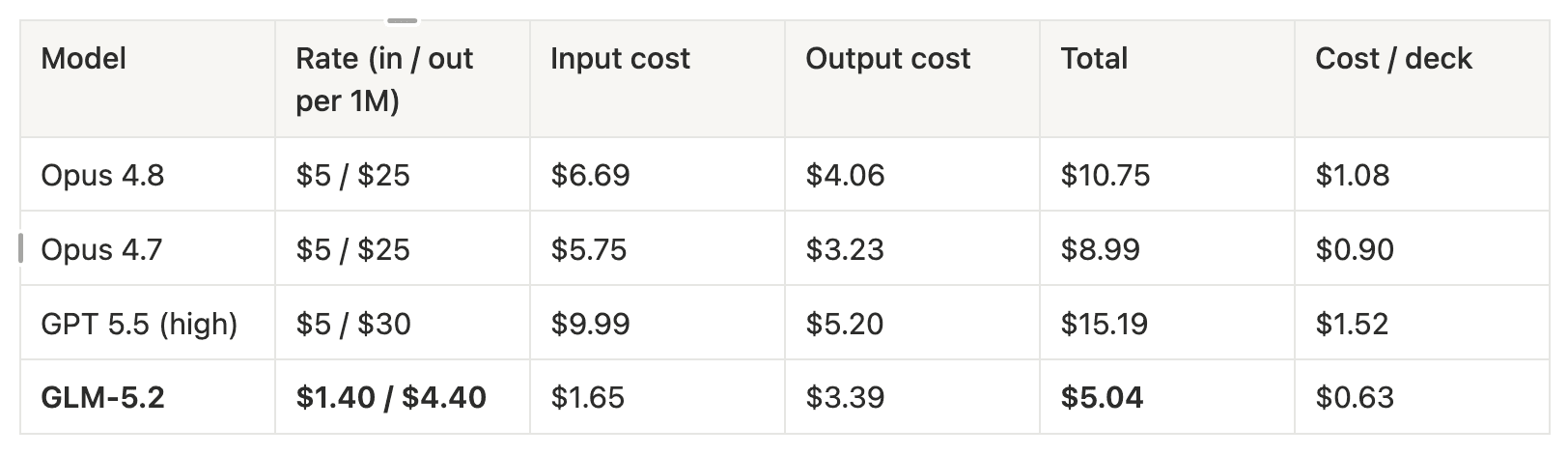
Opus 4.8: highest quality (avg 84.7/100). About 16% above GLM.
GLM-5.2: cheapest at $0.63 per deck (~half of Opus)
Frontier models had 10/10 first-try success. GLM: 3/10 without nudges
GLM: 5–6× more tokens, ~4× slower
For agent design in 2026 - frontier models can step into existing systems and just work with almost no modifications for revenue.
We ran this eval because we build agents for revenue teams. Slide decks are one of the most common requests we see in production, and we care about each model’s ability to do revenue-generating tasks.
Here’s the full breakdown.
The Setup
Task: The agent was given a structured spec describing the slides, content, and layout - these were real requests from customers.
The agent’s job was to execute that spec into a finished PowerPoint using our production harness (PptxGenJS-based).
Data: We tested 10 real slide deck requests.
Judge: Each completed deck was scored by an LLM judge (Claude Opus 4.6) on a weighted 0–100 rubric across content fidelity, structure, visual design, code quality, brand, and spec adherence.
Note: The harness was originally optimized around Opus, so this is best viewed as an agent-fit test rather than a pure model benchmark.
The Initial Results were Brutal for GLM-5.2
First-pass success rate was brutal for GLM: only 3/10 decks produced. It would reason forever without calling the actual deck-writing tools. We added a "retry bounce" (nudge to use tools, up to 3 attempts). This got GLM to 8/10.
Frontier models (Opus 4.8/4.7, GPT-5.5) succeeded on attempt 1 every single time.
Opus Won on Quality
Averaged across the decks each model actually produced:
Opus 4.8: 84.7
Opus 4.7: 82.5
GPT-5.5 (high): 81.1
GLM-5.2: 72.9 (n=8)
The frontier model scores clustered tightly in the low 80s (~3.5 pt spread).
GLM scored ~10-12 pts back, and generated much worse “worst” decks. Multiple GLM decks scored in the 40s because they dropped entire bullet points or body text without any error or warning.

Where GLM Loses
GLM is surprisingly competitive on structure and brand.
However, it performed much worse on two key areas:
Content fidelity (how accurately it includes all the requested content)
Visual design (how clean and professional the slides look).
This gap came mainly from GLM’s rendering issues. For example, on the exact same Org Chart slide from the same spec, Opus 4.8 produces a clean, complete slide. GLM often drops content, so the final slide looks incomplete and broken.
This difference is very noticeable.

Where GLM Wins: The Cost/Performance Tradeoff
GLM is the heaviest model by far, but it’s the cheapest.
Output tokens/deck: GLM ~96k vs. 13-17k for others (4.5-6× more)
Time/deck: GLM took ~13 min per deck vs. 2.5-3.3 min on frontier models
Cost/deck produced (flat June 2026 rates, penalizing failures): GLM $0.63 vs. Opus 4.8 $1.08, GPT $1.52
In other words, GLM is roughly half the cost of Opus 4.8, but it takes 4× longer and produces significantly more tokens due to heavy reasoning and extra tool calls.
GLM's reasoning loops generate massive output and remedial tool churn (highest verify actions/deck).
GPT-5.5 also iterates heavily but more productively.
Opus 4.7 is the cleanest one-shot performer.

Takeaways for AI Engineers
GLM doesn't slot neatly into an Opus-optimized agent harness.
Frontier models (especially Opus family) are drop-in reliable for tasks like slide dekcs.
GPT-5.5 proves a non-Opus model can still compete with strong verification loops.
GLM can delivers real savings if you're willing to invest in orchestration: stricter tool prompting, rendering guardrails, retry logic, and fixes for content-dropping patterns.
Model price isn’t the same as agent price. Token cost is only one piece. In practice, reliability, how well the model uses tools, and how easily it fits into your system matter a lot.
Great to see Snowflake dropping interesting dbt-bench results, and Ramp showing strong signals in finance workflows too.
At Rox, we’re optimizing for revenue impact, rather than benchmark scores. We will continue to experiment more since this shows promise!
Curious what you've seen with GLM in production agents.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.
