A Brief History of Clever Columns

Rox Editorial Team

One of Rox’s flagship features is Clever Columns: scaled research that works across all your accounts. What began as a simple single-turn search has since evolved into a multi-agent system powered by diverse data sources and sophisticated orchestration. As our user base expanded and the sales organizations we supported grew more complex, the research problems they brought us did too - forcing us to rethink and reinvent the underlying architecture at every stage.
Here is the story of the four major versions of Clever Columns and the technical challenges we overcame along the way.
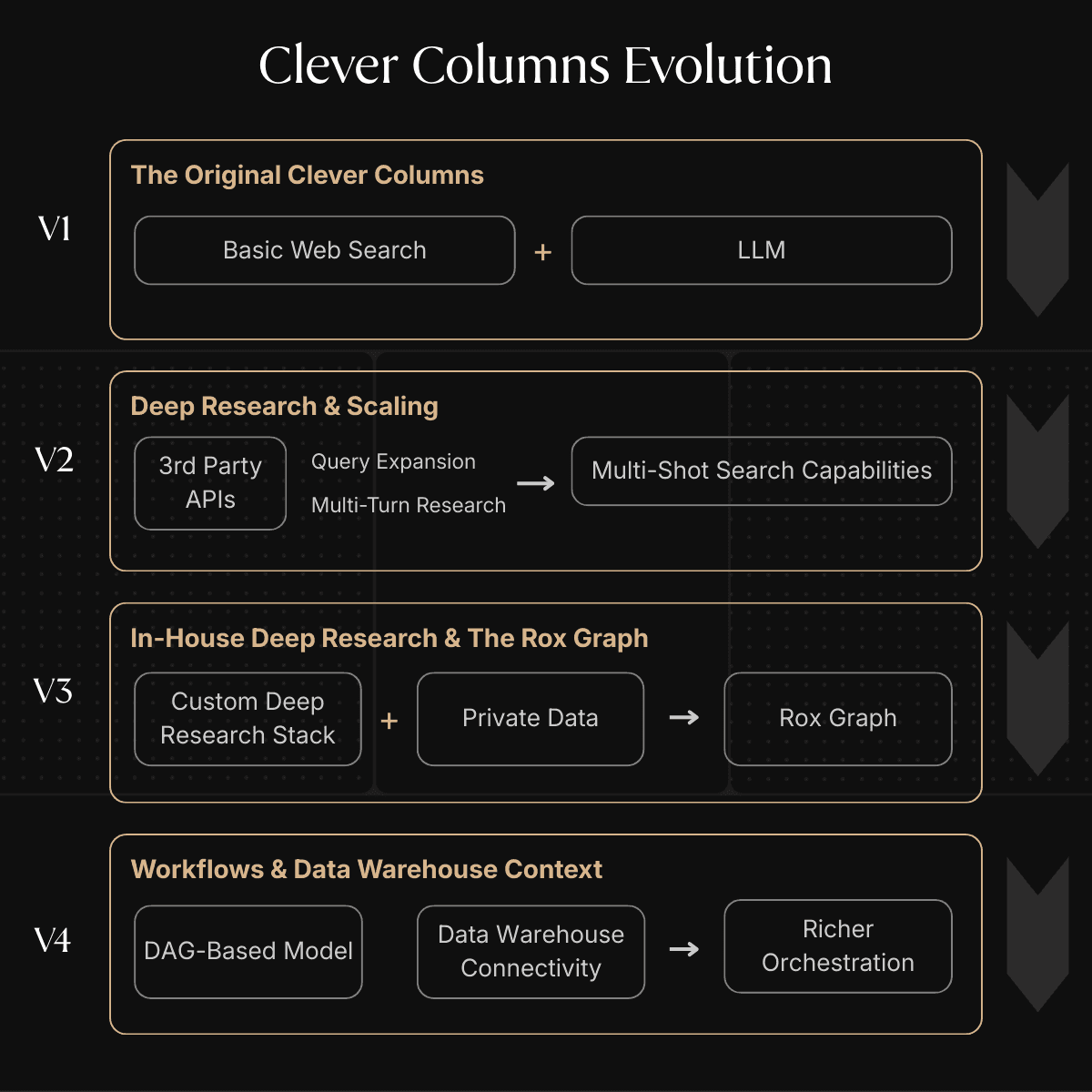
CCV1: The Original Clever Columns (Web Search + LLM)
The first iteration of Clever Columns was simple but effective. It combined basic web search with an LLM.
Approach: A single-turn process where the system would perform a web search based on a user's query and then feed the results into an LLM to generate a summary or answer.
Limitations: It was limited to public web data and couldn't handle complex, multi-step research or access private data.
This lightweight approach was intentional, given Rox’s early days. The company was young, iterating quickly, and focused on delivering value fast before investing in heavier infrastructure.
CCV2: Deep Research & Scaling
As traction for Clever Columns grew, the limitations of the original design became more and more apparent. CCV2 expanded Clever Columns beyond simple web search and added multi-shot search capabilities via query expansion and multi-turn research. With this, the agent could now recursively search (powered by a range of third-party APIs) and summarize to answer questions that required more thought and exploration.
Technical Challenges: Rate Limits, Bursty Activity & Query Expansion
As usage exploded, we faced significant engineering hurdles:
Dealing with Third-Party Failures & Rate Limits
Relying on external APIs meant we had to strictly adhere to their rate limits. We implemented a robust Redis-backed Rate Limiter.
Token Buckets: We used the token bucket algorithm to manage request allowances.
Granular Control: Different limits were set for each provider.
Retry Logic: We built in sophisticated retry mechanisms with exponential backoff to handle transient failures and "Bucket Full" exceptions without dropping user requests.
Balancing Spikes in Activity
User activity often occurred in spikes, triggering research on thousands of accounts simultaneously. We had to implement queueing systems to smooth out the load and ensure that our background workers could process requests efficiently without overwhelming our downstream providers.
As part of the queueing system, we introduced priority levels where user-triggered tasks (treated as foreground work) were routed to higher-priority queues so they could be processed first. We also added org-level load balancing, ensuring that if multiple users in the same organization triggered large bursts of work, the system would distribute capacity fairly across orgs rather than letting one team monopolize all throughput.
Managing Query Expansion Explosion
Multi-shot search introduced a new challenge: poorly constrained query expansion could generate too many downstream searches. A single user question might balloon into dozens of API calls. To keep costs and latency predictable, we added controls around expansion depth, relevance scoring, and pruning heuristics to ensure the agent stayed focused on meaningful branches of research.
CCV3: In-House Deep Research & The Rox Graph
As usage continued to scale, the limitations of third-party APIs couldn’t keep up with our scale or our needs. We needed finer-grained control, consistent performance, and the ability to leverage the rich private data already flowing into the Rox Graph (contacts, deals, sequences, emails, etc.). CCV3 marked a major architectural shift: moving deep research fully in-house.
Specific Tool Calls & Private Data Integration
To make this possible, we introduced a custom deep research stack built around explicit, structured tool calls:
Purpose-built tool interfaces
We designed a suite of tools the model could reason about and call directly, each with well-defined parameters (e.g., account id, date ranges, entity types). This ensured the agent could ask precisely for the data it needed and led to reduced hallucinations, stale lookups, and overly broad queries.
Deep integration with the Rox Graph
These tools were wired directly into the Rox Graph, giving the agent structured access to private sales context (pipeline changes, engaged contacts, historical interactions, etc.) that generic web search or third-party APIs could never reach.
Quality and latency evaluations
Bringing research in-house introduced new risks: regressions in answer quality, slower response times, and inconsistent tool behavior. To guard against this, we built a suite of evals to measure:
tool-call accuracy
multi-step reasoning correctness
latency and cost across the entire research stack
end-to-end answer quality against CCV2 benchmarks
CCV4: Workflows & Data Warehouse Context
The latest evolution, CCV4, introduces Workflows and context from data not directly ingested in the Rox Graph (e.g., data in a warehouse).
Orchestrating Complexity
To support richer, more adaptive research, we moved to a DAG-based model.
Parallel Execution
Independent steps in a workflow can now run in parallel, dramatically improving throughput and reducing end-to-end latency for large, multi-branch research tasks.
Dynamic Branching & Conditional Logic
DAGs let the agent adapt mid-workflow. Based on intermediate results (e.g., “no open opportunities” or “account has multiple subsidiaries”), the system can branch into different paths. This unlocks far richer, context-aware research behaviors than linear pipelines.
Broader Context
By connecting to data warehouses, we can now pull in vast amounts of context that doesn't fit neatly into the standard graph, allowing for even deeper and more personalized research insights.
Config Agent
We introduced a configuration agent that takes a natural language prompt and generates a structured configuration and workflow. This config defines exactly which tools and data sources the research agent should use.
---
Clever Columns has progressed from a single-turn search tool to a multi-agent research system grounded in workflows, DAG orchestration, and rich internal context. Each version has pushed our architecture forward and expanded what’s possible for users. With CCV4, we’ve laid a robust foundation for the next generation of research automation. There’s still very much to build: new agents, richer workflows, and long-horizon capabilities that will push automated research far beyond what’s possible today.
If you want to push the boundaries of what multi-agent systems can do in the real world, we’re hiring.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.

