Building a Unified Knowledge Graph Across Multiple Data Sources

Damon Lin

A Gold Mine of Data, Locked Away
Revenue teams today are surrounded by data, yet starved for actionable insight.
Vast amounts of customer and revenue data are generated across an ever-growing set of systems. Core business records live in CRMs and ERPs and are increasingly replicated to data warehouses. Product usage and activity data is captured as time-series events in data warehouses. Critical context is buried in unstructured sources such as emails, call transcripts, support tickets, and public internet data. While each system provides value on its own, the data within them remains siloed. Traditional analytics and BI tools operate within the boundaries of individual data sources, optimizing for aggregation and reporting rather than for understanding how data connects across systems.
The challenge is not data collection or storage—it is making sense of fragmented data in order to act on it. Revenue teams often struggle to form a coherent view of accounts, opportunities, and customer interactions. Important signals are scattered, context is lost, and answering simple questions often requires manual stitching across dashboards, queries, and conversations. This fragmentation slows decision-making and prevents teams from acting quickly on risk, growth, and opportunity.
Knowledge Graph: Unified Context Layer
Rox creates a unified context layer over an organization’s data by building a custom, proprietary knowledge graph for each organization. The graph models entities, relationships, and contextual signals in a single representation and serves as the foundation for agents that reason over private data.
To support this level of reasoning and flexibility, the knowledge graph must meet two foundational requirements: it must operate directly on enterprise data wherever it lives, and it must adapt to the unique way each organization models its business.
Warehouse-Native and Enterprise-Ready
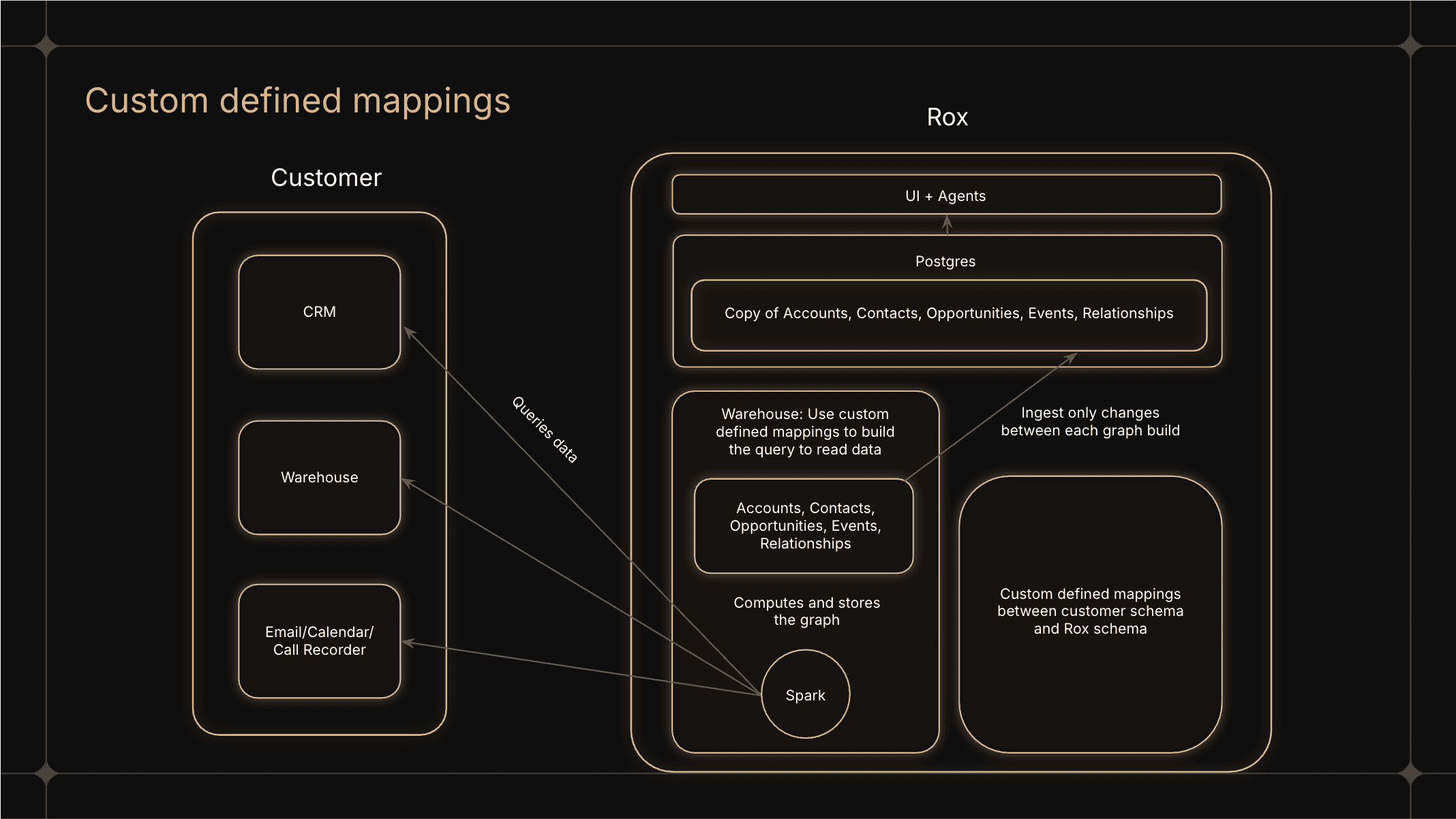
The Rox knowledge graph is warehouse-native by design. Organizational data remains in its existing systems—including data warehouses, operational databases, and external sources—while Rox provides the compute required to query and transform that data into a knowledge graph. No data is copied into Rox-controlled storage, ensuring that data ownership, access controls, and governance remain entirely within the organization’s environment. This architecture makes the system enterprise-ready by default and aligned with security and compliance requirements.
Apache Spark serves as the core compute engine for building the knowledge graph. Spark’s distributed execution model and connector ecosystem allow Rox to operate directly on customer data across a wide range of storage systems, including cloud data warehouses, operational databases, and open table formats.
The knowledge graph is refreshed through a recurring batch pipeline that runs every 30 minutes. Each run incrementally processes new records, applies updates, and removes stale data across all connected sources. This ensures that the graph stays in sync with upstream systems while avoiding overlapping executions and uncontrolled backlogs.
At scale, these pipelines process millions of entities and tens of millions of relationships per organization. Spark’s parallel processing, fault tolerance, and query optimization capabilities allow these workloads to complete reliably within the fixed batch window. As a result, Rox can continuously refresh large knowledge graphs on a predictable schedule while operating entirely within the customer’s data environment.
Custom Mappings and Configurable Relationships
Every organization represents its data differently. The Rox knowledge graph is built to accommodate this reality through custom-defined mappings and relationships. Organizations define how their existing data models map into the Rox representation, allowing entities and attributes to reflect their specific schemas and business logic. Relationships are equally configurable, enabling teams to express how users, accounts, opportunities, and other entities connect in ways that mirror real operational needs. For example, hierarchical relationships can be defined to allow managers to view accounts and opportunities across their reporting structure. This flexibility ensures that each user sees the data that is relevant to them, modeled in a way that matches how the organization actually operates.
Given the schema definitions of a customer’s source tables, Rox allows users to define a one-to-one mapping into a unified Rox schema. These mappings specify how individual columns in source systems correspond to Rox entity attributes, including which fields act as stable identifiers. Data types are automatically inferred and normalized as part of this process, allowing source-specific representations to be cast into consistent formats (e.g. converting integers or strings into timestamps).
On top of these entity mappings, Rox supports explicit join relationships between data across different data systems. By defining which columns can be joined across tables, such as joining a contact table’s account_id field to the id field of an account table, these joins can be used to construct first-class relationships in the knowledge graph, making implicit connections in the source data explicit and queryable.
Beyond basic joins, Rox also supports custom relationship definitions that encode business-specific semantics. For example, multiple relationships may exist between users and accounts, such as the owner of an account versus a solutions engineer supporting an account. These relationships allow the graph to capture not just that two entities are related, but how they are related. Subsets of these relationships can then be used to control visibility and relevance, such as building account assignment rules to determine which accounts a user should see and manage.
All mappings and relationships are evaluated dynamically. Queries over the knowledge graph are computed at runtime using the organization’s specific schema definitions, relationship rules, and access context. This allows Rox to present a consistent interface across organizations while respecting the unique structure, semantics, and operational logic of each customer’s data.
From Warehouse Computation to Real-Time Querying
Each knowledge graph build produces a unified Rox representation of entities and relationships computed at warehouse scale. The output consists of normalized tables for core entities—accounts, opportunities, contacts, and events—along with a relationship table that captures connections between entities. Each entity is assigned a stable Rox identifier while preserving its original source ID for traceability, stored in its own table.
Spark is used to compute and materialize this representation directly in the data warehouse, leveraging distributed execution to process millions of entities and relationships efficiently. While the warehouse serves as the system of record for graph computation, powering interactive use cases requires low-latency reads and high concurrency.
To support this, the entities and relationships are ingested into Postgres as a serving layer optimized for real-time querying by both the UI and agents. Rather than reloading the entire graph on each build, Rox computes diffs between successive builds and applies only inserts, updates, and deletes to Postgres. This incremental approach minimizes data movement, avoids overlapping batch jobs, and keeps UI- and agent-facing data fresh and responsive.
Why This Matters
For revenue teams, this architecture turns fragmented data into a living system of knowledge. Instead of stitching together dashboards, queries, and conversations, teams get a real-time, connected view of their customers that reflects how the business actually operates. By unifying data across sources and making relationships explicit, Rox enables faster understanding, better decisions, and timely action—unlocking value that was always present in the data, but never accessible.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.
