Intelligent Data Gatekeeper

Amol Singh

Not every email belongs in your context graph.
Sounds counter-intuitive right? Isn’t more context better? First, our agents get work done for sellers and all work happens on specific information planes. Our agents must operate on clean trust and permissioning layers, beyond what even our sellers work on top of. Secondarily, our inboxes are drowning with promotional blasts, hr threads, linear/jira notifications and they’ve become a low signal to noise environment. A deny list doesn't cut it. The long tail of "looks legitimate but shouldn't be indexed" is enormous, and it shifts across organizations and industries.
This is the reason at Rox we built a multi-stage ingestion pipeline that combines deterministic rules and intelligent LLM sweeps. Every stage evaluates emails against shared defaults layered with org-specific rules, giving each customer full control over what enters their system. This email ingestion engine fits into a set of smart rule engines shown below in Figure 1 that process incoming data only persisting relevant, anonymized and policy-compliant information while filtering out noise, sensitive leakage, and non-essential content.
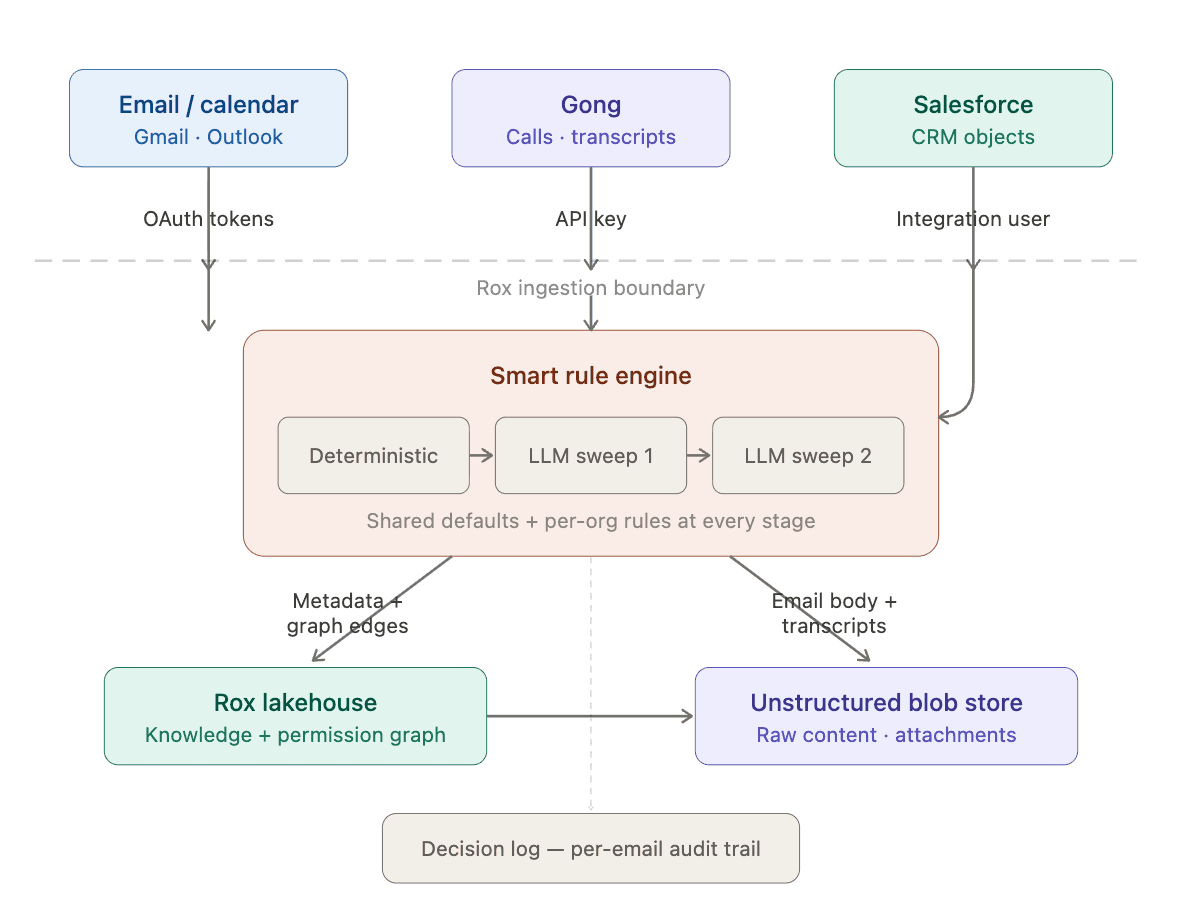
Figure 1 The full smart rule engine that gates which data gets persisted in the knowledge graph and the Rox System
The two-tier rule model
Every filtering stage applies rules in two layers.
Shared baseline. Curated defaults reflecting cross-industry consensus — blocking noreply@ senders, dropping emails labeled "Promotions," flagging HR-related subjects. Maintained by our team, applied to every org unless overridden.
Org-specific configuration. Every rule category from deny lists and keyword patterns to sensitivity thresholds and LLM rules/rubrics can be extended, narrowed, or overridden per org through structured config stored in organization configurations. Two organizations on the same platform can have meaningfully different ingestion behavior without custom code.
This matters because enterprise customers don't want to build governance policy from scratch on day one. They want a system that works out of the box and lets them tighten or loosen the knobs as their compliance team weighs in and inherits permission structures from applications and systems the company already has in place.
How the pipeline works: the Rippling problem
Say Rippling is one of your customers. Your sales team emails their procurement and leadership team regularly and those threads are exactly what the context graph should capture.
But Rippling is also your payroll provider. Periodically, Rippling sends your employees pay stubs, tax documents, benefits updates, etc. Same domain, same company — completely different context.
Here's how the pipeline handles it:
Deterministic filters won't catch this. The domain rippling.com isn't on any deny list — it shouldn't be, because you want to ingest the sales threads. Keyword rules might catch some payroll emails, but subject lines like "Your document is ready" are too generic to filter reliably.
Metadata Sweep might catch it — if the subject line says "Your pay stub for March 2026," the metadata alone is enough. The sender is not a specific known contact in your CRM, the recipients are individual employees rather than a sales thread, and the subject explicitly references payroll. Classified as sensitive, dropped before the body is ever read.
But if the subject is vague — something like "Your document is ready" — sweep 1 doesn't have enough signal. It sees an automated sender and a generic subject, which could be a payroll doc or a contract your sales team is waiting on. It passes the email through.
Full Email Sweep resolves it. It reads the body, sees compensation figures, tax withholdings, and employee-specific financial data, and classifies it as sensitive personal content. The body is never stored and metadata which is encrypted via a one-way hash is stored for your observability. Furthermore, each of these sweeps can run in your VPC, securing all compute as well.
Meanwhile, an email from your actual Rippling contact about a contract renewal flows through the same pipeline, passes both sweeps, and lands in the context graph where it belongs.
This is the class of problem that deny lists can't solve. The same domain is simultaneously a customer you want to track and a vendor sending sensitive employee data. Only a system that evaluates context can make the right call.
Pipeline stages
Deterministic filters
Applies deny lists (shared baseline for common automated senders, org-specific blocked domains and addresses), keyword rules (structured JSON patterns against email subjects), and provider labels/folders (Gmail categories like Promotions and Updates, Outlook folders like Newsletters and Clutter). Each category follows the two-tier model with shared defaults layered with org-specific overrides. Rejected emails are dropped entirely with the specific triggering rule written to the audit log.
Metadata Sweep
Only by accessing the subject line, participants, headers, labels, the metadata sweep catches what deterministic rules can't: promotional emails from legitimate domains, personal threads between colleagues, HR communications from senders you'd normally index. The sensitivity threshold is configurable at the organization level uses a LLM as a judge with a default rubric and set of criteria.
Full Email Sweep
The most expensive step, which is why it only runs on emails that survived everything above or went down a pipeline bypass (configured by organizations). This step is the first point at which the full email body and attachments are retrieved via direct API calls and the content gets evaluates against the org's governance posture and produces structured classification tags that dictate the faith of the email.
Decision log
Every stage writes to an audit log to track what ran, what it decided, why. For the LLM-based sweeps we store: model version and reasoning. For deterministic filters: the specific rule that fired. This closes the enterprise governance loop. When a compliance officer asks "why wasn't this email ingested?" the answer is a queryable log with per-email, per-step decisions.
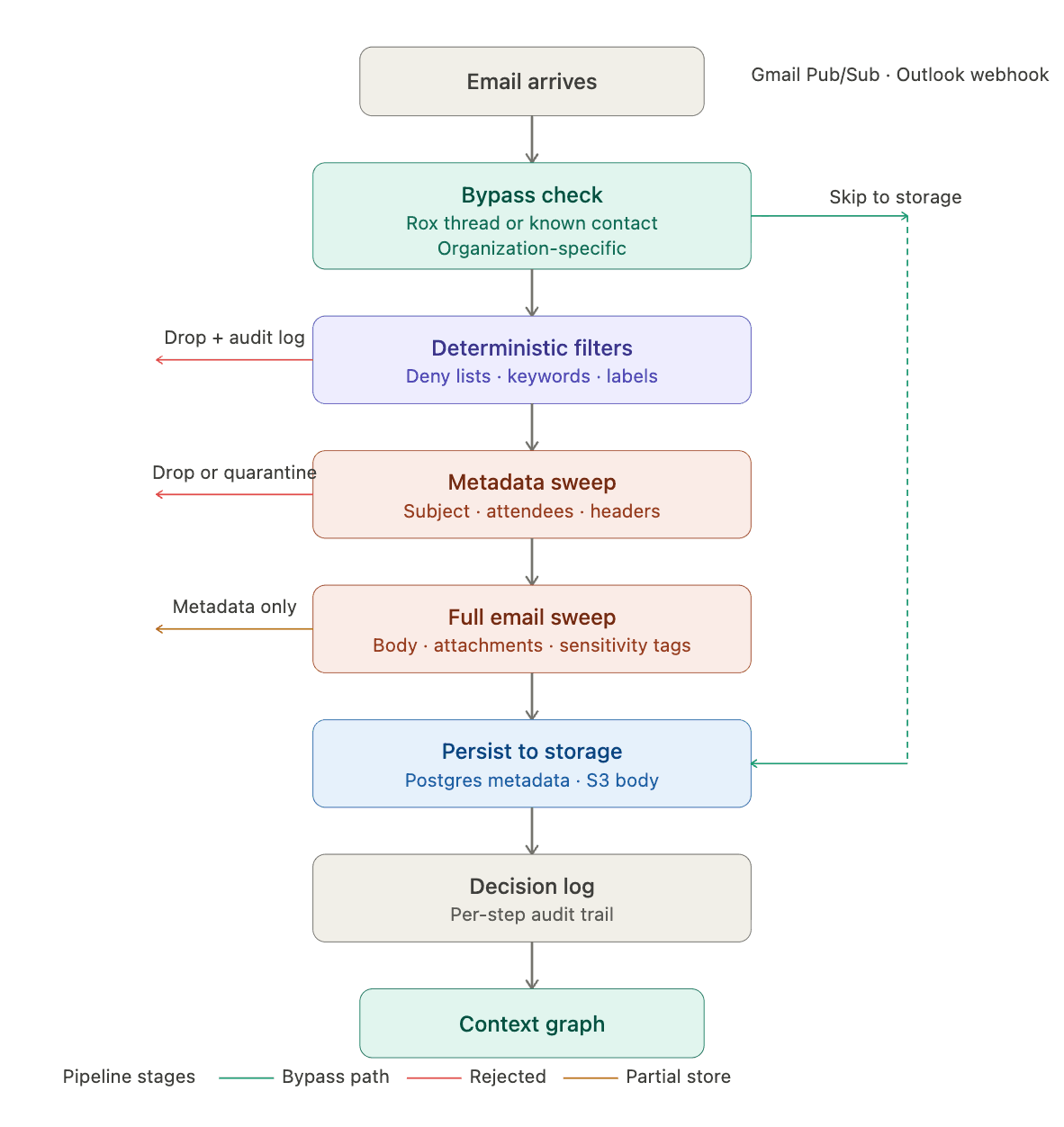
Figure 2 The end to end pipeline for the email ingestion consisting of initial bypass checks, deterministic filter stage and llm-based filtering stages.
What this unlocks
The immediate wins is trust. Enterprise customers evaluating a product that reads their email need a governance story, not a privacy policy. Organization level rules, LLM-based sensitivity classification, and per-email audit logs move the conversation from "can we trust you with our data" to "here's how we want you to handle our data."
The downstream win is context quality. When every email in the context graph has been actively classified, everything built on top improves where meeting briefs carry more signal, relationship intelligence has less noise and agent based features operate with higher confidence.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.



