Building high-accuracy, cost-effective web search agents

Mehul Arora

Sanchit Gupta

“Has Philips announced any new initiatives in the last week?” sounds like a simple question. And if you’re researching a single company, it is. You can spin up ChatGPT Deep Research and get a reasonable answer in minutes.
A large part of GTM relies on publicly available signals. Philips announcing an AI partnerships program and hiring a new Head of AI in the past week, for example, is a strong indicator that they are shifting resources towards making their organization AI ready.
The challenge is scale. GTM teams monitor hundreds or thousands of accounts simultaneously, with signals updating continuously. At that point, “Has Philips announced any new initiatives in the last week?” becomes “Have any of these thousands of companies announced any new initiatives in the last week?”
That’s the problem we set out to solve: batch web research across thousands of accounts, with a high quality bar and a cost structure that makes the system viable in production.
What works for 1 account doesn’t work for 10000
Our first crack at this was naive: an agent that searches, reads, and loops until it finds an answer. And for the first bit, it worked.
But only in the same way that reading Wikipedia for six hours “works.” You keep consuming information, but the context keeps growing and eventually it fills with noise.
In practice, we saw the agent’s context window expand uncontrollably. The agent kept reading and appending, but it never effectively bounded or compressed what it learned.
Concretely, this created two overlapping problems: 1) low response quality, and 2) prohibitive increase in costs.
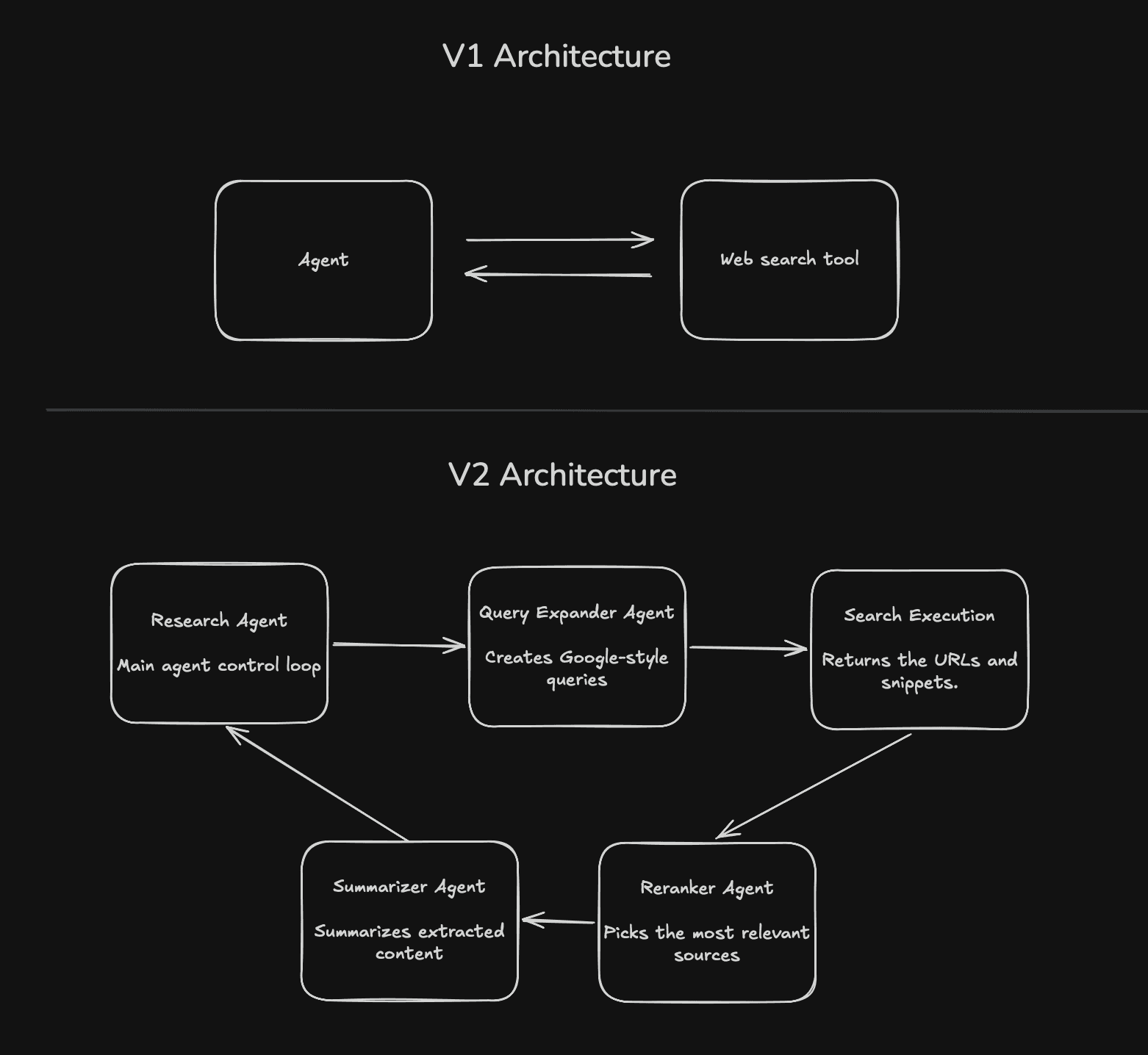
Image: Comparison of V1 and V2 architectures.
In experimenting with alternative approaches, we came across a useful observation: LLMs are really good at writing search queries: the kind of keyword-heavy queries you’d send to a SERP provider. Even when the agent was prompted to generate natural language queries, it would fall back to the google-style queries the underlying LLMs were trained on.
Trying to steer it towards the perfect natural language query felt like resisting the flow. So we decided to lean into these raw, Google-style queries. Instead of forcing the system into a “LLM → search → LLM” loop, we leaned into what it was already good at and broke the problem down.
The main research agent becomes a coordinator. It decomposes the task into smaller sub-questions and decides what to explore next based on what’s already been learned.
The Query Expansion Agent comes up with different phrasings, angles and constraints for research queries. This increases recall and surfaces results that a single query would miss.
The Reranker Agent then does the first real filtering pass. It scores results based on relevance and signal strength, pulling forward sources that are likely to contain actionable information rather than just matching keywords.
The Summarizer Agent reads a small set of high-signal documents and compresses them aggressively into structured takeaways rather than long-form summaries.
This approach came with a tradeoff: the sub agents reads a lot and return little, so information gets lost. But we recover that by making the system iterative. In addition to returning high signal research to the main agent, the summarizer agent identifies gaps, new leads and perspectives for follow-up queries that steer the main agent towards uncovered ground. Over time, the system builds coverage incrementally through a sequence of focused, high signal passes.
Proof of work
Getting the right answer is hard, proving you got it for the right reasons is harder.
Evaluating agents is fundamentally different from evaluating single-turn LLMs. In the single-turn case, you have a clean setup: input, output, grader. Agents search, reason, iterate, and make decisions along the way, so failures are often partial and hard to localize. And when something goes wrong, it’s unclear what went wrong. Did it miss the right source? Misread it? Overfit to something irrelevant? Or just take a slightly different path this time?
With our agents, we focus on verifying the process: what sources were retrieved, how they were used, and whether the final output is grounded in high-quality evidence. We create sandbox environments, replay runs, and log every step of the agent’s interaction with the same tools it would have access to in a production environment. We then use LLM graders to evaluate both the trajectory and the outcome. And we do this across multiple runs to account for variance.
We built our grading rubric for web research agents based on Anthropic’s work:
Did the agent look in the right places?
Did the agent use authoritative sources?
Did the final answer actually follow from what the agent found?
Did the agent do so consistently?
Better evals give us clearer targets. Clearer targets lead to better agents. Better agents expose new failure modes, which force better evals. So the way we think about this isn’t “build the agent, then evaluate it.” It’s building both together. Each iteration tightens the system a bit more.
What next?
This system works, but research agents are far from solved. Building high-quality golden datasets, defining correctness in ambiguous real-world scenarios, and better capturing user’s query intent itself are all open problems.
Early solutions we’re trying include personalizing our product to each user with agent memory, implementing explicit and implicit feedback collection loops in our product, and constantly improving our evaluation harnesses.
If you want to build at the forefront of agents – we’re hiring.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.
