Building a Reliable AI Infrastructure Layer

Pranav Pusarla

Rox runs thousands of different agents over its various products. That means millions of model calls per day that need to execute reliably and at scale all day long. At that volume, infrastructure matters.
We rely on a combination of standard techniques to keep things running smoothly: rate limiting, fallbacks, dynamic routing. However, as things scale, you begin to realize that standard techniques break under the pressure. That's where the fun begins: breaking it down to the basics and innovating on the fly.
Here are a few of our stories.
Rate Limiting
Every platform that uses AI agents depends on multiple model providers: OpenAI, Anthropic, open source…, to name a few. And with that usage comes rate limits in two common forms: RPM (Requests per Minute) and TPM (Tokens per Minute). What providers don't always tell you is that once you hit those limits, they quietly start throttling your service, creating unpredictability at exactly the wrong moments.
So we built our own internal rate limiting service. The goal was simple: take back control and protect the reliability of our product. We used Redis via the pyrate-limiter package, wrapped with a retry layer and jitter to handle traffic spikes gracefully.
We shipped it to production. The next morning, we had a SEV-0.
Redis memory usage had gone through the roof. Core parts of our product were coming to a halt. After a few hours of digging, we found the culprit: pyrate-limiter uses a Leaky Bucket algorithm that stores every request as an individual timestamp. For a single request carrying 20,000 tokens, the package was making 20,000 separate Redis calls: one per token.
Ex. pseudocode from package
You can imagine our reaction. We were routing millions of tokens through this thing.
We went back to basics, researched industry approaches, and landed on the rolling window algorithm: a method that groups all requests within a time window into a single bucket, storing usage as a simple key-value pair. We wrote the bucket implementation from scratch using our own custom LUA scripts and patched it into the package. The Redis call overhead dropped dramatically. While it's an approximate estimation compared to the full preciseness of Leaky Bucket, you can increase the number of buckets to get comparable accuracy. For our use case, it was the perfect fit.
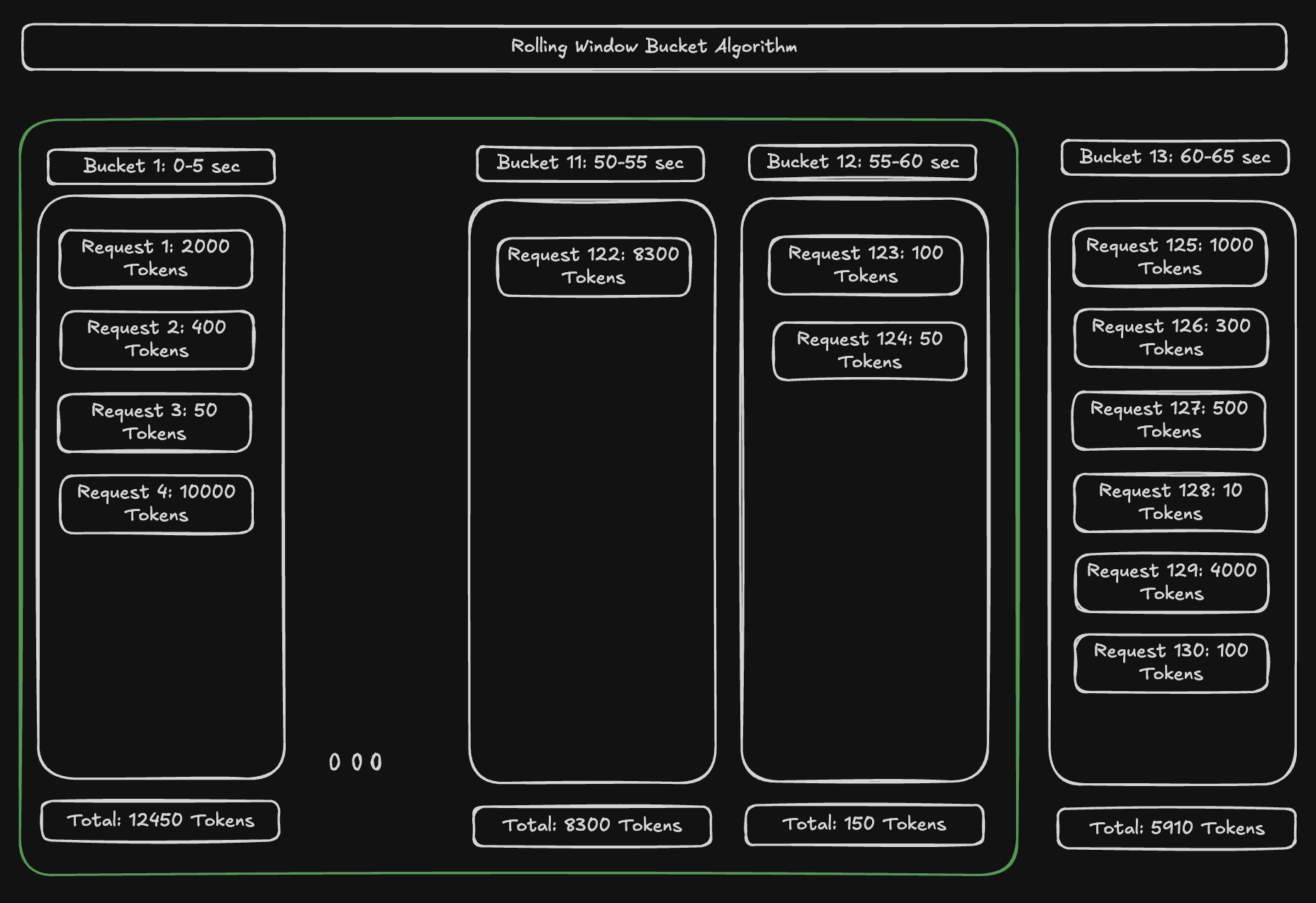
Figure 1. Rolling Window Bucket Algorithm
We shipped the fix. It's holding up well.
Search Provider Reliability
One of our most popular features is Clever Columns, which lets users generate answers to any question across a list of companies/accounts. Under the hood, it works by scraping public URLs through search providers and extracting the information needed to answer each query.
But what happens when a search provider goes down? We built a fallback system with multiple layers of redundancy. What we didn't anticipate were the problems that came with juggling multiple external services.
External providers offer SDKs to make integration easy and secure and for a while, that convenience was great. Then we started noticing something strange: bizarre lag spikes under traffic, potential memory leaks, unusually high CPU usage. After days of investigation, we found the source.
One of our primary search providers was opening a brand new HTTP connection for every single request. It was baked right into their SDK. Every new connection means a full TCP and TLS handshake, expensive in both latency and compute. The fix was connection pooling: we patched their internal parameters on our end to use our own pooling client. It worked, until the same issue surfaced with another search provider.
Ex. code that caused bug
That kicked off one of the longest internal debates we've ever had. One side wanted to ditch the SDK approach entirely. Patching each new provider's internals wasn't scalable. It was better to own the logic ourselves and talk directly to the source of truth: the API. The other side was worried about the maintenance burden. If we bypass the SDK, we have to track every upstream API change ourselves.
We chose to trust our engineers’ capabilities and build from the ground up. We scrapped the SDK, built our own connection pool from scratch, and created lightweight provider clients that talk directly to each API.
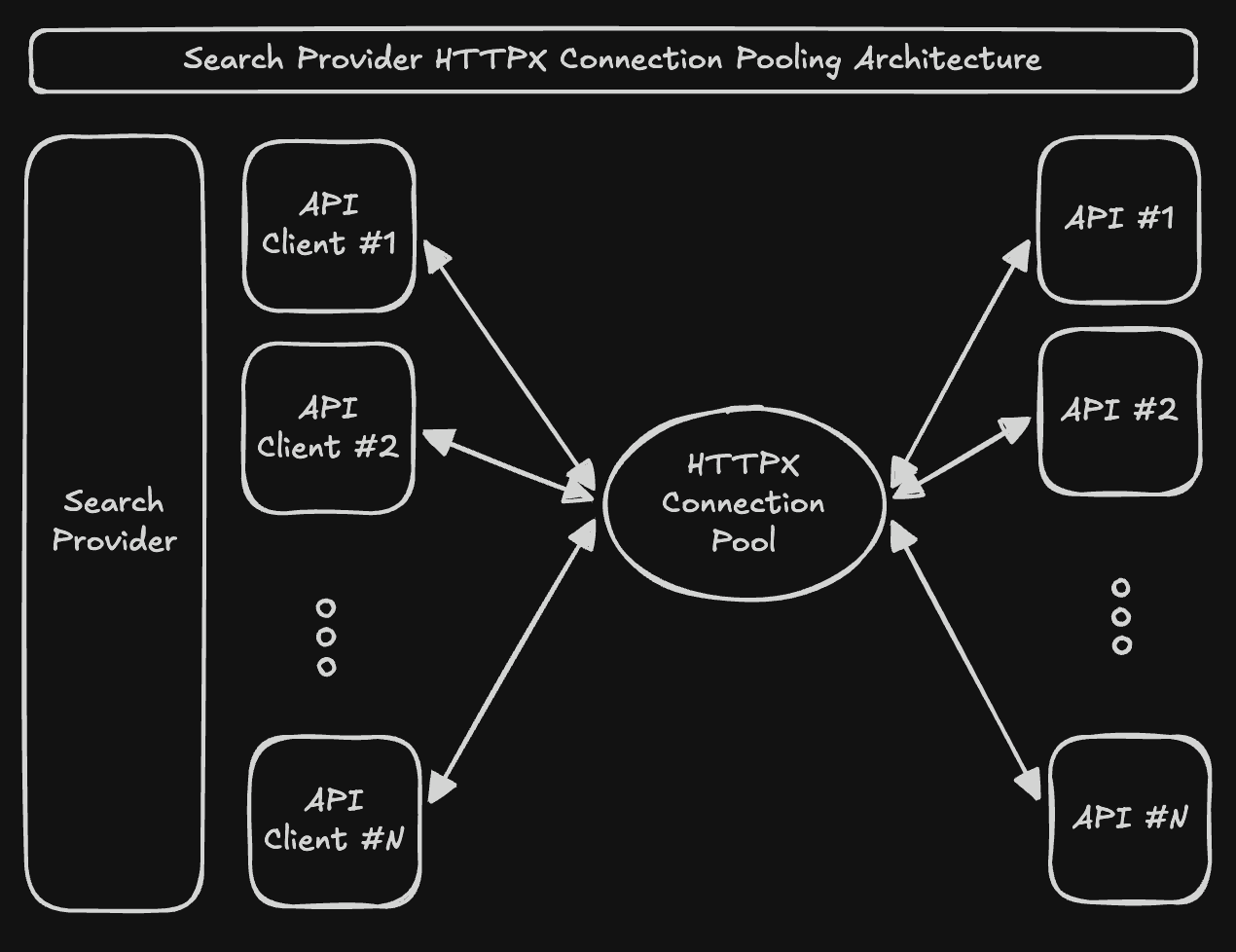
Figure 2. HTTPX connection pooling architecture
A week later, it was in production ready before the weekend. And within days after that, we were able to scale our search providers by 3x without being concerned with external provider behavior.
Reliability as a Service
There's a phrase that gets repeated a lot in our office: "Think from first principles." It sounds simple, but it becomes essential when you're building the layer that holds everything else up.
Whenever we start a new infrastructure problem, we ask ourselves three questions:
Why does this need to exist?
How will this affect the user's experience?
How do we build this to scale from the very beginning?
In a space moving as fast as AI, what makes any platform truly usable isn't just the intelligence of the models but the reliability underneath them. The two problems we described here are just a small part of the engineering framework we're building every day.
Similar Articles
We build with the best to make sure we exceed the highest standards and deliver real value.
